프롤로그
단 한 줄의 R 코드도 직접 짜지 않고, Chat GPT과 대화를 통해서만 HR 데이터를 분석하는 작업을 해보았다. 놀랐던 것은 Chat GPT가 짜준 코드에 에러가 발생해서 해결해 달라고 요청하니 사과와 함께 바로 수정된 코드를 만들어줬다는 것이다.
정말 여러 사람들의 입에 오르내리는 Chat GPT다. 데이터 분석가 지인에게 Chat GPT가 코드도 기가막히게 잘 짜준다는 이야기를 들었다. 그래서 HR에 대한 Data를 추출한 뒤 분석할 때 Chat GPT를 활용해보았다. 정말 잘 될까? 의구심이 더 컸다. 그러나 나의 의구심을 비웃기라도 하듯, Chat GPT는 몇 번의 시행착오를 했지만 대단한 성능을 보여줬다. 더욱 놀라운 것은 이 과정이 정말 '사람'같았다는 것이다.
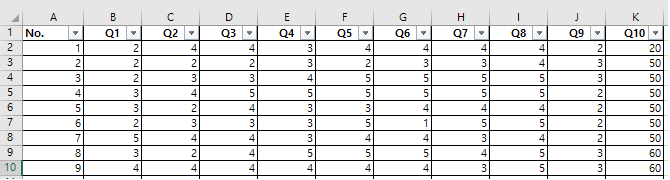
이 글을 통해 여러분은 Chat GPT와 '어떻게' 대화해야 데이터 분석 코드를 '잘' 짤 수 있는지에 대한 실마리를 찾게 될 것이다. 임의로 구성한 이 데이터 셋은 관측치의 번호가 매겨진 No. 칼럼과 Q1~Q10의 10개 문항에 대한 응답 칼럼으로 되어있다. 칼럼의 모습을 엑셀로 보면 다음과 같다.
이제 분석을 실행해 보겠다. 처음으로 상관분석을 다룬다. 상관분석이란 특정 변수간 어떤 '관계'가 있는지를 드러내는 분석기법이다. 결과값은 음의 상관, 0, 양의 상관으로 나올 수있다. 이 때 0이라는 것은 상관이 없다는 것이 아니라 '선형'상관이 아니라는 의미이다.
나의 첫 질문이다. 질문과 답변은 글상자 안에 있으며, 편의상 Chat GPT의 답변은 Blue 계열의 색상의 폰트를 썼다.
R로 데이터 분석을 하고 싶어. 데이터는 data 폴더에 있고 파일명은 raw.xlsx 야. 이 파일은 11개의 칼럼으로 구성되어 있어. Q1번부터 Q10번까지의 칼럼을 분석해서 각 칼럼 간의 상관관계를 확인하고 시각화할 수 있는 R코드를 짜줘. 결측치가 있는 행은 모두 삭제해 줘.
GPT가 대답했다.
데이터 분석을 위해서는 우선 R을 설치해야 합니다. R을 설치한 뒤 다음과 같이 코드를 작성하면 됩니다.
# 필요한 라이브러리를 불러옵니다
library(readxl)
library(dplyr)
library(ggplot2)
# 데이터를 불러옵니다
df <- read_excel("data/raw.xlsx")
# 결측치가 있는 행을 모두 삭제합니다
df <- na.omit(df)
# Q1 ~ Q10 컬럼만 선택합니다
df_selected <- df %>% select(Q1:Q10)
# 상관관계를 계산합니다
correlation <- cor(df_selected)
# 시각화합니다
ggplot(melt(correlation), aes(x=Var1, y=Var2, fill=value)) +
geom_tile() +
scale_fill_gradient2(low="blue", high="red", mid="white",
midpoint=0, limit=c(-1,1), space="Lab",
name="correlation") +
theme_minimal() +
labs(title="Correlation Matrix", x="Variables", y="Variables")위 코드에서 read_excel 함수를 사용하여 "data/raw.xlsx" 파일을 불러옵니다. na.omit 함수를 사용하여 결측치가 있는 행을 모두 삭제합니다. 그리고 select 함수를 사용하여 Q1 ~ Q10 칼럼만 선택합니다. 상관관계를 계산하기 위해 cor 함수를 사용하고, 시각화하기 위해 ggplot 함수를 사용합니다. 시각화를 위해 melt 함수를 사용하여 데이터를 재구성합니다.
시각화 결과는 Q1 ~ Q10 컬럼 간의 상관관계를 나타내는 히트맵입니다. 이를 통해 어떤 변수들이 서로 관련이 있는지 파악할 수 있습니다.
하지만 이 코드를 실행하면 오류가 발생한다. melt 함수를 쓸 수 있는 reshape2를 불러오지 않았기 때문이다. 물론 내가 직접 불러올 수도 있지만 에러 코드를 직접 질문해 보기로 했다.
Error in melt(correlation) : could not find function "melt" 에러를 해결해 줘
죄송합니다. melt 함수는 reshape2 라이브러리에 포함된 함수이기 때문에, 코드 상단에 library(reshape2)를 추가해줘야 합니다. 다음은 수정된 코드입니다.
# 필요한 라이브러리를 불러옵니다
library(readxl)
library(dplyr)
library(reshape2)
library(ggplot2)
# 데이터를 불러옵니다
df <- read_excel("data/raw.xlsx")
# 결측치가 있는 행을 모두 삭제합니다
df <- na.omit(df)
# Q1 ~ Q10 컬럼만 선택합니다
df_selected <- df %>% select(Q1:Q10)
# 상관관계를 계산합니다
correlation <- cor(df_selected)
# 시각화합니다
ggplot(melt(correlation), aes(x=Var1, y=Var2, fill=value)) +
geom_tile() +
scale_fill_gradient2(low="blue", high="red", mid="white",
midpoint=0, limit=c(-1,1), space="Lab",
name="correlation") +
theme_minimal() +
labs(title="Correlation Matrix", x="Variables", y="Variables")GPT는 재빠르게 사과(...)하고 수정해 둔 뒤 당당한 말투(?)로 말했다.
이제 melt 함수가 정상적으로 동작할 것입니다.
위의 코드 결과는 히트맵이 전부일뿐, 상관계수가 보이지 않는다. 내가 다시 질문했다.
히트맵 안에 상관계수가 들어가게 시각화해 줘
히트맵 안에 상관계수가 들어가도록 하려면, geom_text 함수를 추가하여 시각화해 줄 수 있습니다. 다음은 수정된 코드입니다.
# 필요한 라이브러리를 불러옵니다
library(readxl)
library(dplyr)
library(reshape2)
library(ggplot2)
# 데이터를 불러옵니다
df <- read_excel("data/raw.xlsx")
# 결측치가 있는 행을 모두 삭제합니다
df <- na.omit(df)
# Q1 ~ Q10 컬럼만 선택합니다
df_selected <- df %>% select(Q1:Q10)
# 상관관계를 계산합니다
correlation <- cor(df_selected)
# 시각화합니다
ggplot(melt(correlation), aes(x=Var1, y=Var2, fill=value, label=value)) +
geom_tile() +
geom_text(size=3) + # 텍스트 추가
scale_fill_gradient2(low="blue", high="red", mid="white",
midpoint=0, limit=c(-1,1), space="Lab",
name="correlation") +
theme_minimal() +
labs(title="Correlation Matrix", x="Variables", y="Variables")이제 geom_text 함수를 사용하여 히트맵 안에 상관계수를 추가했습니다. size 인자를 사용하여 텍스트의 크기를 조정할 수 있습니다.
그러나 이 또한 내가 원하던 결과는 아니다. 소수점 처리가 되지 않아 계수를 알아볼 수 없었기 때문이다.(아래 그림 참고)
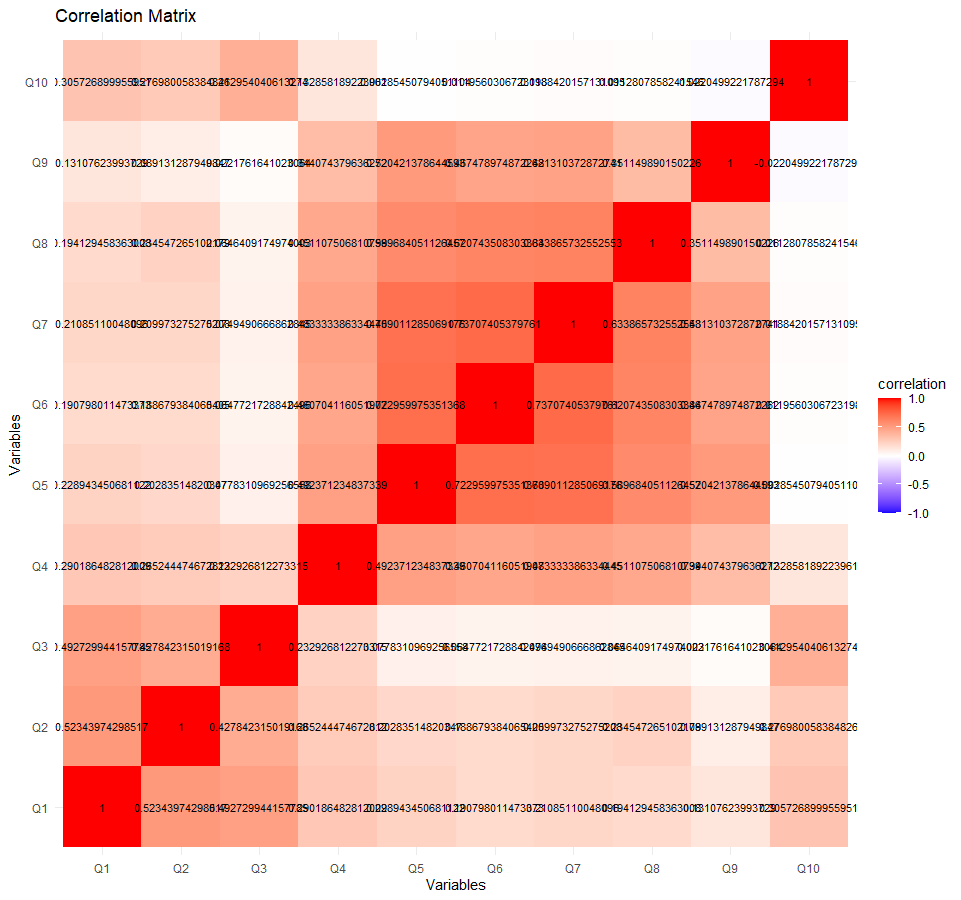
결국 나는 다시 질문(요청)한다.
상관계수가 너무 길어. 소수 둘째 자리까지만 보여줘
round 함수를 사용하여 상관계수를 소수점 둘째자리까지 반올림할 수 있습니다. 다음은 수정된 코드입니다.
# 필요한 라이브러리를 불러옵니다
library(readxl)
library(dplyr)
library(reshape2)
library(ggplot2)
# 데이터를 불러옵니다
df <- read_excel("data/raw.xlsx")
# 결측치가 있는 행을 모두 삭제합니다
df <- na.omit(df)
# Q1 ~ Q10 컬럼만 선택합니다
df_selected <- df %>% select(Q1:Q10)
# 상관관계를 계산합니다
correlation <- cor(df_selected)
# 소수점 둘째자리까지 반올림합니다
correlation <- round(correlation, 2)
# 시각화합니다
ggplot(melt(correlation), aes(x=Var1, y=Var2, fill=value, label=value)) +
geom_tile() +
geom_text(size=3) +
scale_fill_gradient2(low="blue", high="red", mid="white",
midpoint=0, limit=c(-1,1), space="Lab",
name="correlation") +
theme_minimal() +
labs(title="Correlation Matrix", x="Variables", y="Variables")이제 round 함수를 사용하여 상관계수를 소수점 둘째자리까지 반올림했습니다.
수정된 코드를 실행하니 적절한 수준의 결과가 완성되었다.(아래 그림 참고)
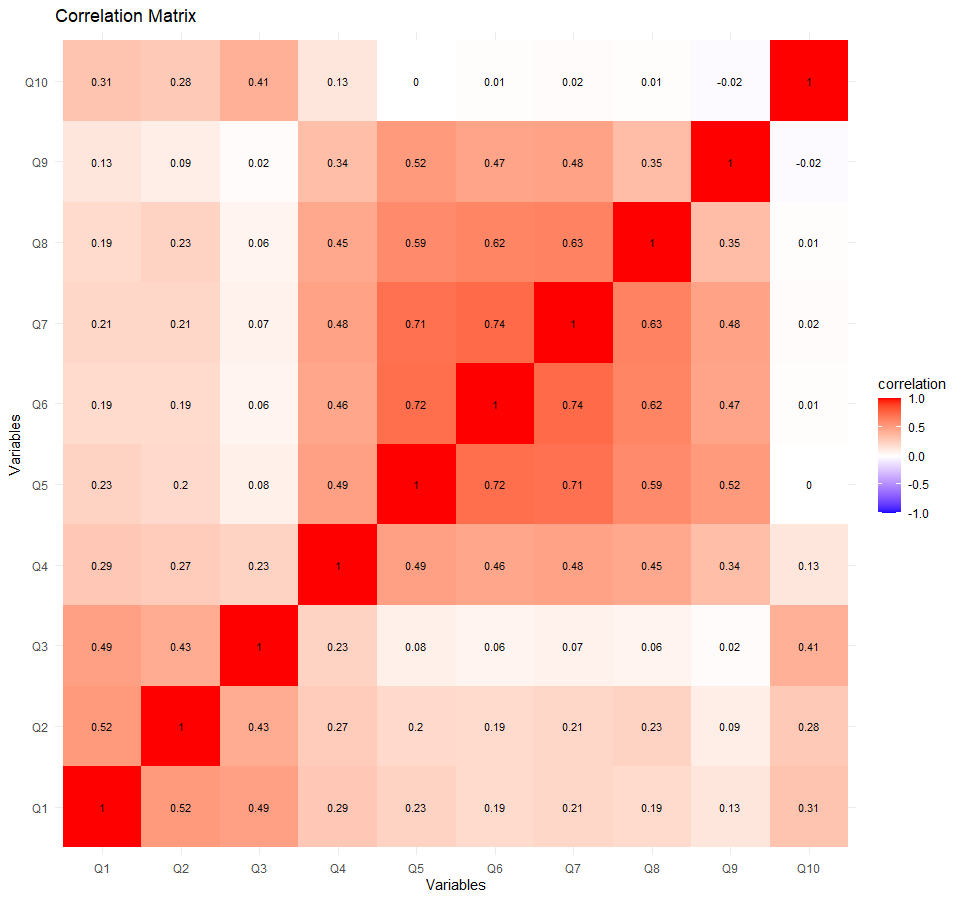
Chat GPT를 활용해서 첫 [대화형 분석]을 해보니 다음과 같은 사실을 알게 되었거나 느끼게 되었다.
- Chat GPT는 동일한 질문을 던졌을 때 동일한 답변(코드)을 주지 않는다.
- Chat GPT는 코드에 각주를 달아주는 경우가 더 많다.(안달아주는 경우도 있다.)
- Chat GPT의 답변을 이해할 수 있는 정도의 지식은 알고 있어야 한다. 즉, 코딩을 할 수 있는 사람이 Chat GPT를 활용할 때 더 효과적이고 실수가 없다.
- Chat GPT는 항상 에러 없는 코드를 짜주지 않는다. 에러가 발생하면 고쳐달라고 요구해야 한다.
- Chat GPT는 에러가 발생하면 '사과한다.' 사과한다라는 시나리오는 인간의 의식적 행동이다. 이 행동을 집어넣은 이유는 각자의 상상에 맡긴다.
다음 글에서는 회귀분석과 군집분석을 해보겠다. 원래 하던 나의 일을 더 효율적으로 하게 만들어 줄 것이라는 기대가 크다.
'01.HR Data & Analytics' 카테고리의 다른 글
| HR Analytics 시작하기 (0) | 2023.02.20 |
|---|---|
| 데이터로 덕질하기_이적의 발자취_4.가사 속에 담긴 감정의 의미 (0) | 2023.02.18 |
| 데이터로 덕질하기_이적의 발자취_3.이적 가사로 감정분석을 해보자! (0) | 2023.02.12 |
| 데이터로 덕질하기_이적의 발자취_2.어떤 단어를 가사에 많이 썼을까? (0) | 2023.02.10 |
| 데이터로 덕질하기_이적의 발자취_1.언제 가장 많은 곡을 발표했을까? (0) | 2023.02.09 |